
2. 입력값 확인 기능 끔

3. 입력창 메세지 바꿈

4. 구조화 구문

5. 오류 --문자열 크기 작음

//빈 테이블 생성
SQL> create table t1
2 as select empno, ename, hiredate
3 from emp
4 where 1 != 1;
SQL> create table t2
2 as select empno, ename, sal
3 from emp
4 where 0=1;
--다중 테이블 insert
SQL> insert all
2 into t1 values (empno, ename, hiredate)
3 into t2 values (empno, ename, sal)
4 select empno, ename, hiredate,sal
5 from emp
6 where deptno=10;
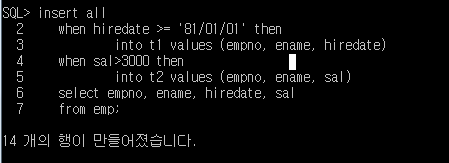
SQL> insert all
2 when hiredate >= '81/01/01' then
3 into t1 values (empno, ename, hiredate)
4 when sal>3000 then
5 into t2 values (empno, ename, sal)
6 select empno, ename, hiredate, sal
7 from emp;

SQL> insert first
2 when sal <= 1000 then
3 into sal1000 values (empno, ename, sal)
4 when sal <= 3000 then
5 into sal3000 values (empno, ename, sal)
6 else
7 into salmax values (empno, ename, sal)
8 select empno, ename, sal
9 from emp;
--테이블 생성
CREATE TABLE SALES_DATA
(EMPNO NUMBER(4),
SPRING_SALE NUMBER(9),
SUMMER_SALE NUMBER(9),
AUTUMN_SALE NUMBER(9),
WINTER_SALE NUMBER(9));
INSERT INTO SALES_DATA VALUES (100, 3000, 5000, 6000, 7000);
INSERT INTO SALES_DATA VALUES (200, 4000, 2000, 3000, 5000);
INSERT INTO SALES_DATA VALUES (300, 6000, 3000, 4000, 4000);
INSERT INTO SALES_DATA VALUES (400, 3000, 1000, 5000, 2000);
CREATE TABLE SALES_SEASON
(EMPNO NUMBER(4),
SEASON_CODE CHAR,
SALES NUMBER(9));
--피벗팅 INSERT
SQL> insert all
2 into sales_season values ( empno, '1', spring_sale)
3 into sales_season values ( empno, '2', summer_sale)
4 into sales_season values ( empno, '3', autumn_sale)
5 into sales_season values ( empno, '4', winter_sale)
6 select empno, spring_sale, summer_sale, autumn_sale, winter_sale
7 from sales_data;

--권한부여
SQL> conn system/123456
SQL> grant create any directory to scott;
--외부파일 읽어드릴 폴더이름 지정
SQL> create directory emp_dir as 'c:\oracle'; --디렉토리명을 emp_dir로 설정
--외부 테이블 파일 읽기
SQL> create table extemp (
2 empno number, ename varchar2(10), job varchar2(10), mgr number, hiredate date)
3 organization external
4 (type oracle_loader
5 default directory emp_dir
6 access parameters
7 (records delimited by newline
8 badfile 'BAD_EMP'
9 logfile 'LOG_EMP'
10 fields terminated by ','
11 (empno char,
12 ename char,
13 job char,
14 mgr char,
15 hiredate char date_format date mask "YY/MM/DD")
16 )
17 location('EMP.TXT')
18 )
19 parallel 5
20 reject limit 200;
--예제 주소 파일 읽기
SQL> create table zipcode(
2 zipcode char(7),
3 sido varchar2(6),
4 gugun varchar2(27),
5 dong varchar2(39),
6 ri varchar(67),
7 bunji varchar2(18),
8 seq number(5))
9 organization external(
10 type oracle_loader
11 default directory emp_dir
12 access parameters(
13 records delimited by newline
14 badfile 'BAD_EMP'
15 logfile 'LOG_EMP'
16 fields terminated by ','(
17 zipcode char,
18 sido char,
19 gugun char,
20 dong char,
21 ri char,
22 bunji char,
23 seq char)
24 )
25 location('zipcode.csv')
26 )
27 parallel 7
28 reject limit 200;
--출력
SQL> select * from zipcode
2 where rownum<10; ---불러올 행의 갯수 제한하기

SQL> select empno, ename, hiredate, rank() over (order by hiredate) rank
2 from emp;

///PARTITION BY 그룹별 랭킹
SQL> select empno, ename, deptno, sal,
2 rank() over (partition by deptno order by sal desc) rank
3 from emp;

--동 순위가 있어도 그 다음 순위를 건너띄지 않음
SQL> select empno, ename, deptno, sal,
2 rank() over (order by sal desc) rank,
3 dense_rank() over (order by sal desc) dense_rank
4 from emp;

--최대값 1을 기준으로 순위를 0~1사이의 값으로 표시
SQL> select empno, ename, deptno, sal,
2 rank() over (order by sal desc) rank,
3 cume_dist() over (order by sal desc) cume_dist
4 from emp;

--CUME_DIST와 유사하지만, 계산 방법은 약간 다르다
--PERCENT_RANK = (파티션 내 자신의 RANK-1)/(파티션 내의 행 개수-1)
SQL> select empno, ename, deptno, sal,
2 rank() over (order by sal desc) rank,
3 percent_rank() over (order by sal desc) percent_rank
4 from emp;

--파티션 내의 행들을 N개로 분류하여 행의 위치를 표시한다
SQL> select empno, ename, sal,
2 ntile(7) over (order by sal desc) ntile
3 from emp;

--파티션 내에 행들에 대하여 차례로 순번을 표시한다
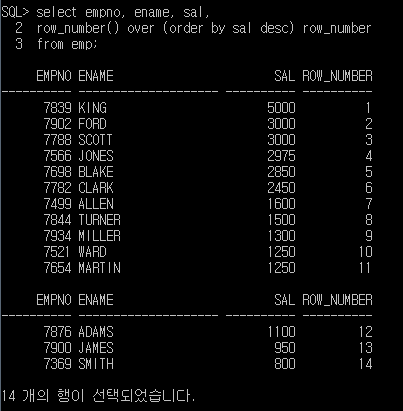
SQL> select empno, ename, sal,
2 row_number() over (order by sal desc) row_number
3 from emp;
--테이블 생성
SQL> create table emp20
2 (empno number(4),
3 ename varchar2(10),
4 job varchar2(10),
5 sal number(7,2));
--데이터 입력
SQL> insert into emp20(empno, ename, job, sal)
2 select empno, ename, job, 0
3 from emp
4 where deptno = 20;
--데이터 확인
SQL> select * from emp20;
--향상된 merge
SQL> merge into emp20 n
2 using emp o
3 on (n.empno = o.empno)
4 when matched then
5 update set
6 n.ename = o.ename,n.job = o.job, n.sal = o.sal
7 where o.job='CLERK'
8 when not matched then
9 insert (n.empno, n.ename, n.job, n.sal)
10 values (o.empno, o.ename, o.job, o.sal)
11 where o.job='CLERK';

--REGEXP_LIKE
SQL> select * from reg_test
2 where regexp_like(name, '^ste(v|ph)en$');

--REGEXP_INSTR
SQL> select name,
2 regexp_instr(name, '[^[:alpha:]]')
3 from reg_test
4 where regexp_instr(name, '[^[:alpha:]]')>1;
//[ : 표현식의 시작
//^ : NOT
// [:alpha:] : 알파벳
// ] : 표현식의 끝
--REGEXP_SUBSTR
SQL> select regexp_substr(name, '[^ ]+')
2 from reg_test;
--첫 번째 공백이 나타나기 전의 문자열을 리턴

--REGEXP_REPLACE
SQL> select regexp_replace(name, '(.)', '₩1 ')
2 from reg_test;
--각 문자 뒤에 공백을 추가

SQL> conn system/(비밀번호)
SQL> grant create view to scott;
**뷰 생성
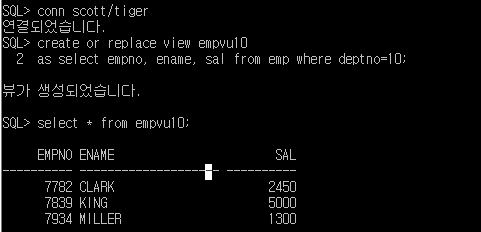
SQL> conn scott/tiger
SQL> create or replace view empvu10
2 as select empno, ename, sal from emp where deptno=10;
**뷰 사용
SQL> select * from empvu10;
SQL> desc user_views;
SQL> select view_name, text from user_views;

SQL> select empno from empvu10;
SQL> select empno from empvu10 where empno=7782;

SQL> create view salvu10
2 as select empno, ename, sal*12 //에러남
3 from emp where deptno=10;
SQL> create view salvu10
2 as select empno, ename, sal*12 year_sal //컬럼명 지정함
3 from emp where deptno=10;

SQL> create view salvu20 (id, name, year_sal)
2 as select empno, ename, sal*12
3 from emp where deptno=10;

SQL> create view dept_avg_vu (name, avg_sal)
2 as select d.dname, avg(e.sal)
3 from dept d, emp e
4 where d.deptno = e.deptno
5 group by d.dname;
SQL> select * from dept_avg_vu;

SQL> drop view salvu20;

SQL> select * from (select empno, ename, sal from emp where deptno=10);

SQL> select d.dname, e.maxsal
2 from dept d, (select deptno, max(sal) maxsal
3 from emp
4 group by deptno) e
5 where d.deptno = e.deptno; //인라인 뷰를 조인에 활용함

SQL> select rownum, ename, sal
2 from (select ename, sal
3 from emp
4 order by sal desc)
5 where rownum <=5;

SQL> select rownum, e.ename, e.sal, d.loc
2 from dept d, (select ename, sal,deptno
3 from emp
4 order by sal desc) e
5 where e.deptno= d.deptno and rownum<=5;

SQL> create sequence emp_empno_seq
2 increment by 10
3 start with 10
4 maxvalue 100
5 nocache
6 nocycle;
//시퀀스 확인
SQL> desc user_sequences;
SQL> select sequence_name, min_value, max_value, increment_by, last_number
2 from user_sequences;

SQL> select emp_empno_seq.nextval from dual;
SQL> select emp_empno_seq.currval from dual; //nextval로 불러와야지 사용가능

SQL> ALTER SEQUENCE EMP_EMPNO_SEQ
2 INCREMENT BY 2
3 MAXVALUE 9000
4 NOCACHE
5 NOCYCLE;
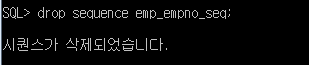
//시퀀스 삭제
SQL> drop sequence emp_empno_seq;
SQL> create index emp2_ename_idx on emp2(ename);

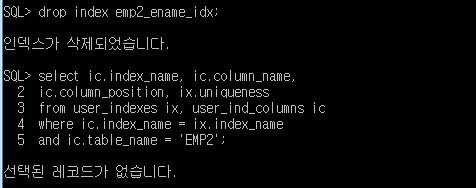
SQL> select ic.index_name, ic.column_name,
2 ic.column_position, ix.uniqueness
3 from user_indexes ix, user_ind_columns ic
4 where ic.index_name = ix.index_name
5 and ic.table_name = 'EMP2';

SQL> drop index emp2_ename_idx;
SQL> alter table emp2
2 add constraint emp2_empno_pk primary key(empno);
//primary key를 삭제하면 인덱스도 사라짐

SQL> conn system/123456
SQL> grant query rewrite to scott;
//인덱스 생성
SQL> create index lower_job_idx
2 on emp2(lower(job));

SQL> grant create synonym to scott;
//생성
SQL> create synonym e for emp2;

SQL> select * from e where lower(ename)= 'smith';

SQL> desc user_synonyms;
SQL> select synonym_name, table_name from user_synonyms;

SQL> drop synonym e;
//공용동의어 생성
SQL> create public synonym hr_emp for hr.employees;
//다른사용자 권한 부여
SQL> grant select on hr.employees to scott;
//다른사용자 동의어 접속
SQL> select * from hr_emp where first_name='Steven';

SQL> create user tom
2 identified by jerry; //생성후 해당 사용자 바로 접속 불가함
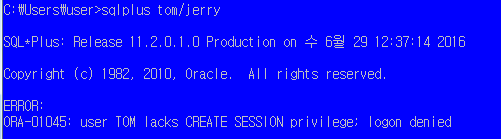
SQL> grant create session to tom;
**테이블생성 권한 부여
SQL> grant create table to tom;
**테이블공간 사용 권한 부여
SQL> grant unlimited tablespace to tom;

SQL> alter user tom
2 identified by jerry; //관리자와 계정본인 둘다 가능함


SQL> alter user tom account lock;
**계정 잠금 해제
SQL> alter user tom account unlock;

SQL> desc all_users;
SQL> select username, user_id created from all_users;

SQL> select * from scott.emp;
select * from scott.emp

SQL> grant select on emp to tom;
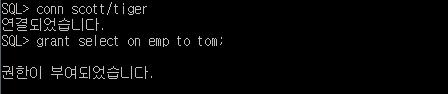

SQL> grant update (loc) on dept to tom;

SQL> update scott.dept set loc='뉴욕' where deptno=10;
SQL> update scott.dept set dname='회계' where deptno=10; //에러남

SQL> select grantee, table_name, grantor, privilege
2 from user_tab_privs_made;

SQL> select owner, table_name, grantor, privilege
2 from user_tab_privs_recd;

SQL> revoke select on dept
2 from tom;
SQL> revoke select on emp
2 from tom;

SQL> create role newuser;
//롤에 권한 부여
SQL> grant create session, create table to newuser;

SQL> create user newuser1
2 identified by 123456;
//사용자에 롤 부여
SQL> grant newuser to newuser1;


SQL> create table emp2 as select * from emp;
SQL> insert into emp2
2 values(8000,'RJU','MANAGER', 7934, sysdate, 2000, null, 40);
SQL> commit;
//접속경로 설정

SQL> conn system/123456
SQL> create public database link link3
2 connect to scott identified by tiger
3 using 'REMOTE';
//링크 연결
SQL> select * from emp2@link2 where empno=8000;

SQL> select deptno, job, sum(sal)
2 from emp
3 group by rollup(deptno, job);

SQL> select deptno, job, sum(sal)
2 from emp
3 group by cube(deptno, job);

SQL> select deptno, job, sum(sal),
2 grouping(deptno),
3 grouping(job)
4 from emp
5 group by rollup(deptno, job);
//0을 리턴하는 경우 --해당 행이 집계 연산에 포함되었음.

SQL> select deptno, job, mgr, sum(sal)
2 from emp
3 group by grouping sets
4 ((deptno,job,mgr),
5 (deptno,mgr),
6 (job,mgr));

SQL> select empno, job, deptno
2 from emp
3 where (job, deptno) in
4 (select job, deptno
5 from emp
6 where empno in (7369,7499))
7 and empno not in (7369,7499);
//사번이 7369 또는 7499번인 직원과 직급 및 부서코드가 동일한 사원 + 본인을 제외

SQL> select empno, job, deptno
2 from emp
3 where job in
4 (select job
5 from emp
6 where empno in (7369,7499))
7 and deptno in
8 (select deptno
9 from emp
10 where empno in (7369,7499))
11 and empno not in (7369,7499);
//사번이 7369 또는 7499번인 직원과 관리자사번이 같거나 직급이 같은 사원 +본인 제외

SQL> select ename, sal
2 from emp e
3 where sal>(select avg(sal)
4 from emp
5 where e.deptno=deptno); //서브쿼리 안에 메인쿼리의 열이 들어가있음

SQL> select empno, ename
2 from emp e
3 where exists (select 'X'
4 from emp
5 where e.empno = mgr);

SQL> with
2 dept_sal as (
3 select d.dname, sum(e.sal) as sal_sum
4 from dept d, emp e
5 where d.deptno = e.deptno
6 group by d.dname),
7 dept_avg as (
8 select avg(sal_sum) as sal_avg
9 from dept_sal)
10 select *
11 from dept_sal
12 where sal_sum>(select sal_avg
13 from dept_avg)
14 order by dname;

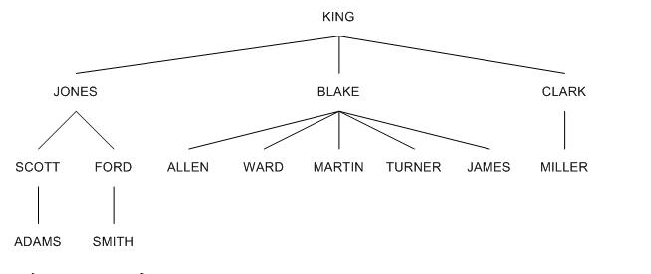
SQL> select empno, ename, mgr
2 from emp
3 start with ename= 'KING'
4 connect by prior empno=MGR;

SQL> select lpad(ename, length(ename) + (level*2)-2, ' ') name
2 from emp
3 start with ename = 'KING'
4 connect by prior empno = mgr;


SQL> select lpad(ename, length(ename) + (level*2)-2, ' ') name
2 from emp
3 where ename != 'FORD'
4 start with ename='KING'
5 connect by prior empno = mgr;

SQL> select lpad(ename, length(ename) + (level*2)-2, ' ') name
2 from emp
3 start with ename = 'KING'
4 connect by prior empno = mgr
5 and ename != 'FORD';
